Diabetes Prediction System
My Role
Machine Learning Engineer – Full Pipeline & Data Analytics
- Data Integrity Assessment: Comprehensive null-value checks and structural analysis
- Ensemble Model Development: Implementing and tuning Random Forest Classifier
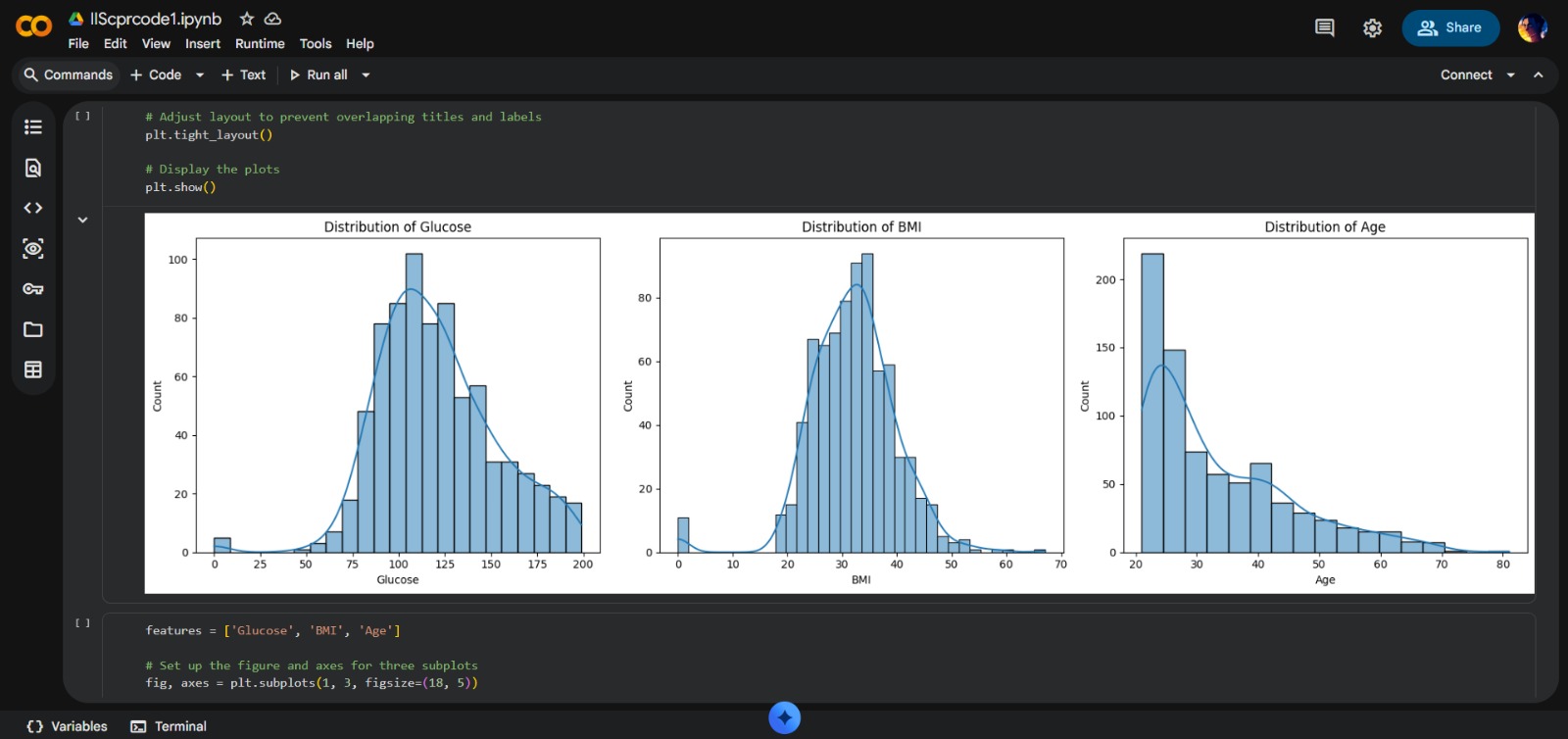
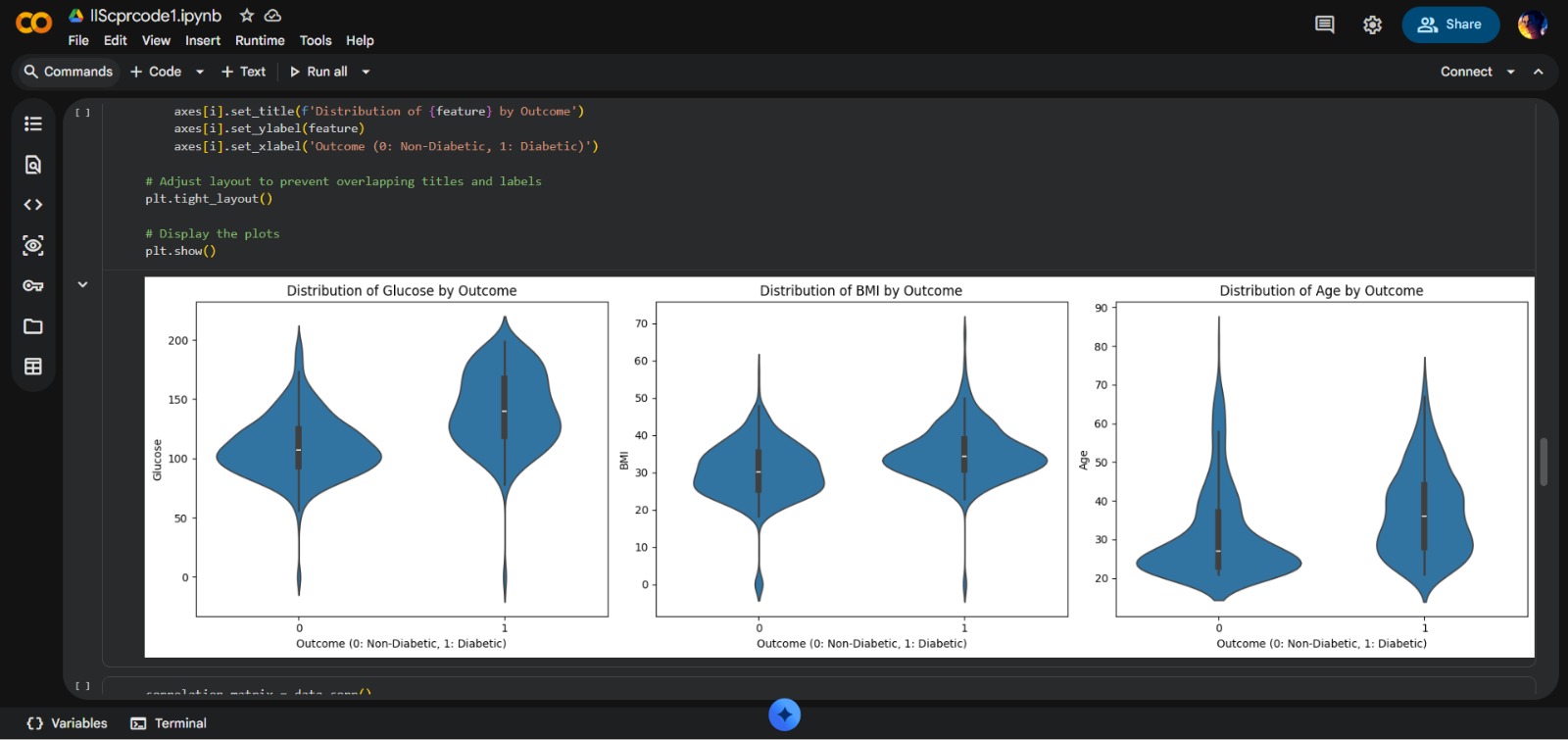
- Exploratory Data Analysis: Designing multi-variate visualizations (Histograms, Violin Plots)
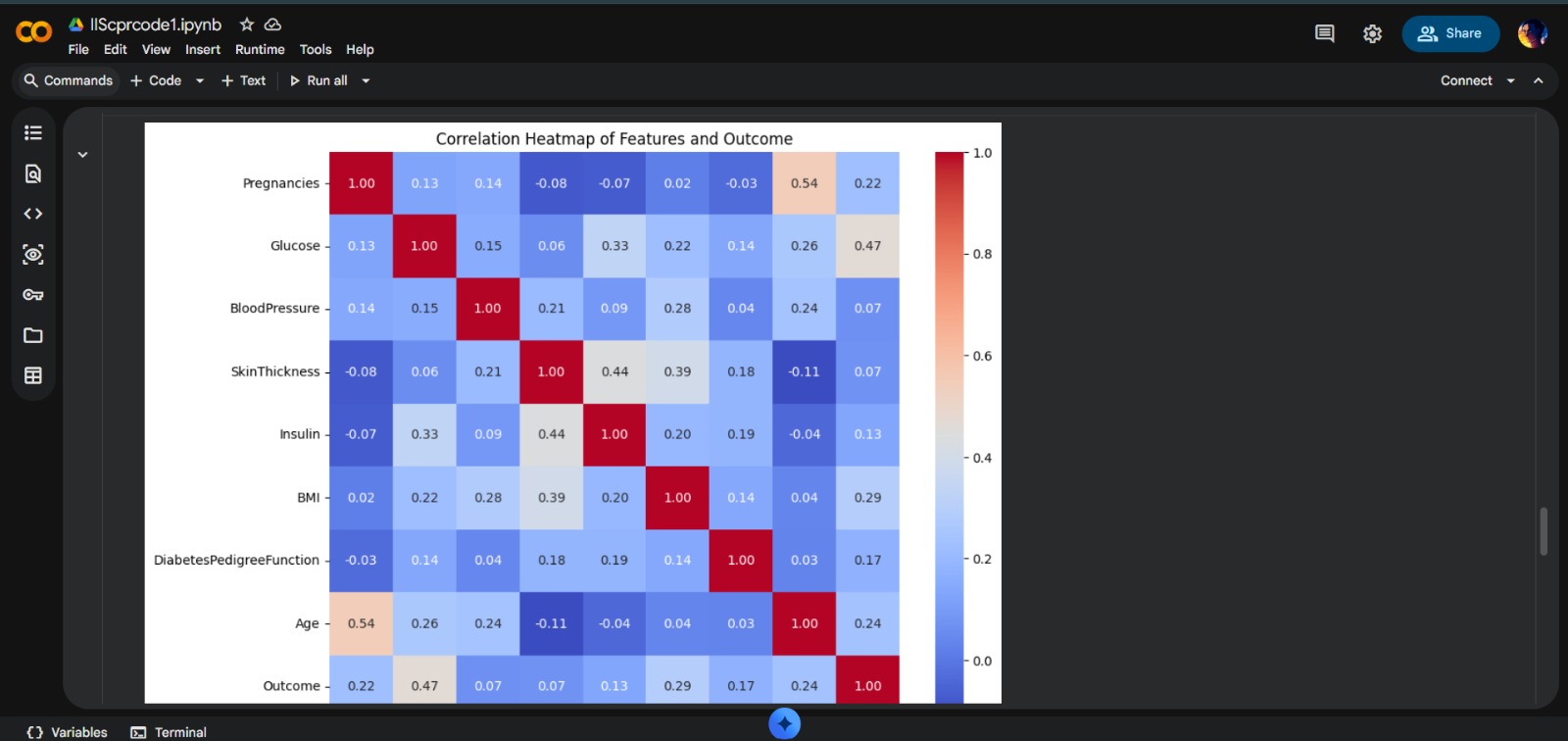
- Statistical Correlation Mapping: Generating Pearson Correlation Heatmap for feature impact
- System Persistence: Model serialization with joblib for real-time inference
Project Highlights
- Visual Storytelling: Transformed raw clinical data into intuitive graphical insights
- High Accuracy Standards: Rigorous testing on 80/20 data split for reliability
- Robust Preprocessing: Handled multi-dimensional features with clean code structure
- Deployment-Ready: Fully serialized model (.joblib) for mobile health app integration
- Healthcare Focus: Demonstrates ensemble learning power in medical diagnostics