AI Text-to-Image Generator
My Role
Generative AI Developer – Model Integration & Pipeline Engineering
- Model Ingestion: Implementing StableDiffusionPipeline from RunwayML repository
- Hardware Acceleration: Configuring NVIDIA CUDA cores for GPU-accelerated generation
- API Authentication: Managing secure handshakes with Hugging Face Hub
- Pipeline Optimization: Engineering memory-efficient processing workflows
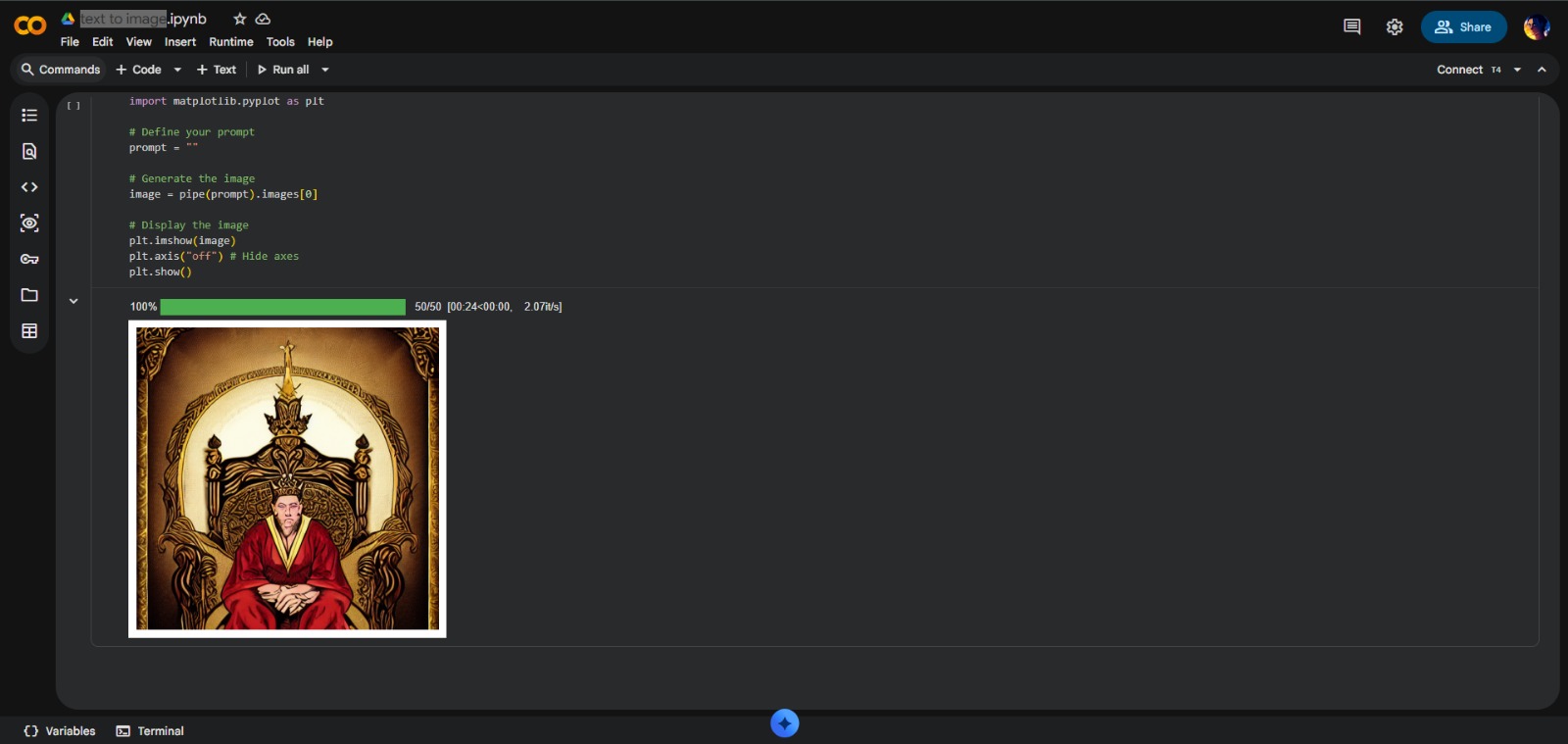
- Visual Output Orchestration: Rendering generated images directly in development environment
Project Highlights
- Cutting-Edge Stack: Demonstrates proficiency in Generative AI technologies
- Cloud-Native Development: Fully optimized for Google Colab with GPU/TPU acceleration
- Token Security: Implements best practices for API security with private access tokens
- Zero-Shot Learning: Generates images for concepts never specifically trained on
- High-Performance: Image generation in seconds rather than minutes